Full-motion deepfakes are coming soon, as "Animate Anyone" signals
With Animate Anyone, it would soon be possible to create animation of people based solely on their photos, which would lessen the threat of deepfakes using still images.

With Animate Anyone, it would soon be possible to create animation of people based solely on their photos, which would lessen the threat of deepfakes using still images.
Scientists at the Institute for Intelligent Computing at Alibaba Group have created a novel method for creating generative videos. This method significantly improved over earlier methods like DreamPose and DisCo, which were notable in the summer but are now seen as old-fashioned.
While Animate Anyone's capabilities are not novel, they have progressed past the problematic stage of being viewed as a "janky academic experiment." They are now deemed "good enough if you don't look closely." As far as we know, the next phase is to get to the point where it's "good enough," meaning that people won't bother to examine it closely since they'll assume it's real. At the moment, text exchanges and still photos are in this stage, leading to misunderstandings and doubts about reality.
Like the one mentioned, image-to-video models extract elements like stance, patterns, and facial features from a reference image, such as a fashion photo of a model wearing a dress. After that, these features are projected onto a sequence of slightly different-posing images that can be used for motion capture or extracted from another movie.
Although earlier models demonstrated feasibility, numerous problems could have been improved. As the model has to create realistic elements, such as how a person's hair or sleeve might move when they turn, hallucinations were a significant issue. This results in many strange images, significantly detracting from the final video's credibility. However, the opportunity persisted, and Animate Anyone has significantly improved—though it is still far from flawless.
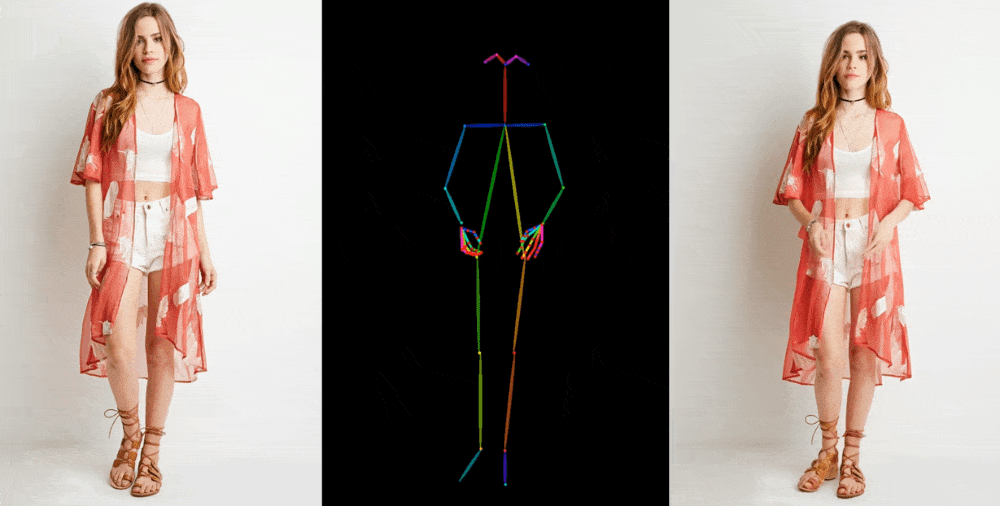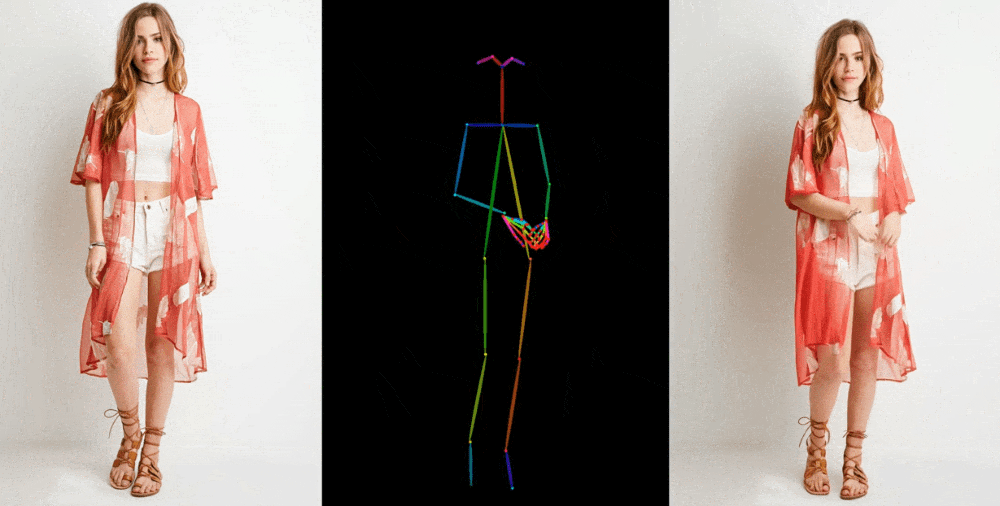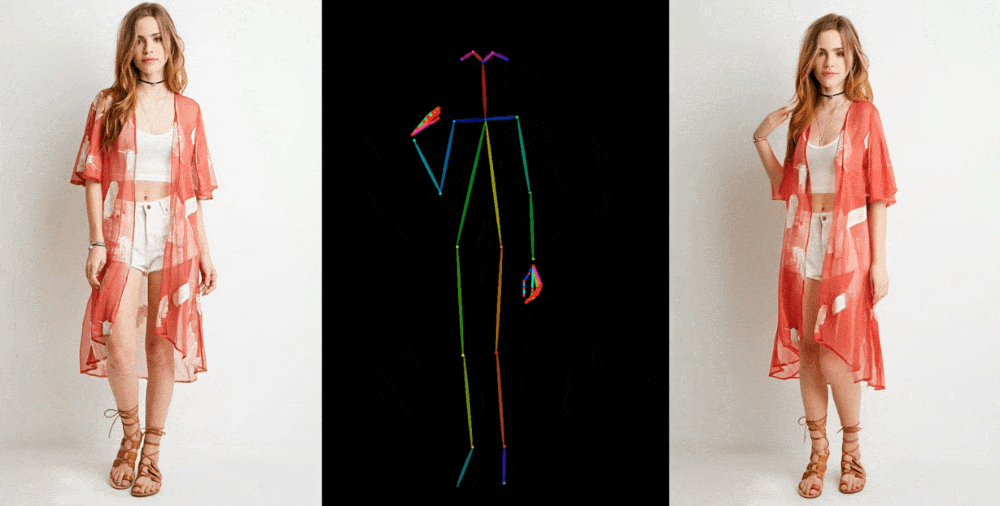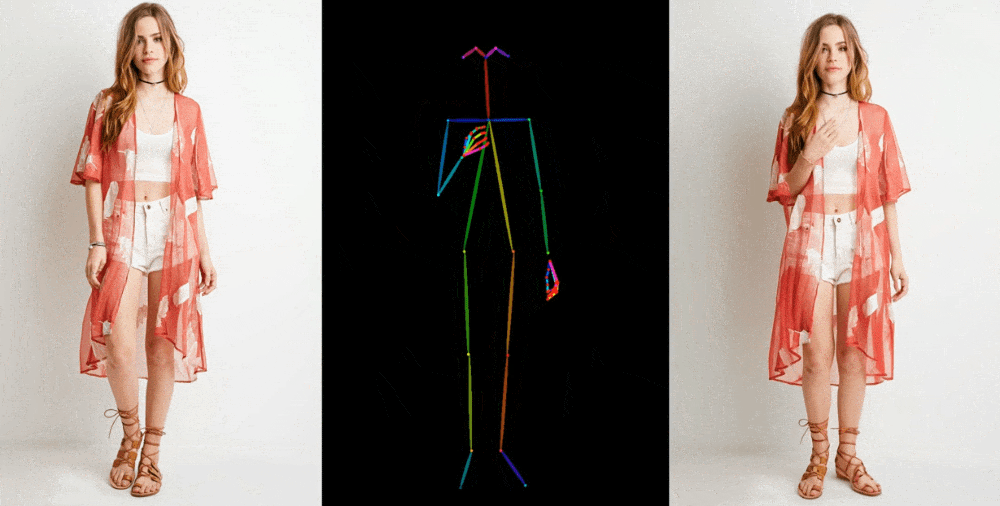
The paper highlights a new intermediate step that "enables the model to comprehensively learn the relationship with the reference image in a consistent feature space, which significantly contributes to improving appearance detail preservation." However, only some people are interested in the technical details of the new model. Enhancing the preservation of fundamental and intricate details will lead to better-generated images since they will have a more substantial ground truth to work with.
They present their findings in a few different settings. Fashion models adopt random positions without losing their shape or the design of their clothes. A realistic, dancing 2D anime character comes to life. Lionel Messi does a few routine motions.
They could be better, particularly regarding the hands and eyes, which present unique challenges for generative models. Furthermore, the most accurate postures closely resemble the original; for example, the model finds it challenging to keep up if the subject turns around. However, it represents a significant improvement over the prior state of the art, which generated many more artifacts or entirely lost crucial information like a person's attire or hair color.
The idea that an evil actor or producer might make you do almost anything with a single high-quality photo of you is unsettling. When combined with speech recognition and facial animation technology, they could also have you express anything simultaneously. Though things in the AI world rarely stay that way for very long, the technology still needs to be simplified and stable for widespread deployment.
At least the team still needs to release the code to the public. The creators state on their GitHub page that they are "actively working on preparing the demo and code for public release." While we cannot guarantee a solid release date, please be assured that we intend to make the demo and source code available.
When dancefakes appear on the internet in droves, will chaos ensue? We will undoubtedly learn more quickly than we would like.

